In a previous post, I wrote about using Splunk to monitor network health and connectivity. While building that project, I thought it would be nice if I could build a more generic application which could be used to perform ad hoc data analysis on pre-existing data without having to go through a complicated process each time I wanted to do some analytics.
So I built Splunk Lab! It is a Dockerized version of Splunk which, when started, will automatically ingest entire directories of logs. Furthermore, if started with the proper configuration, any dashboards or field extractions which are created will persist after the container is terminated, which means they can be used again in the future.
A typical use case for me has been to run this on my webserver to go through my logs on a particularly busy day and see what hosts or pages are generating the most traffic. I’ve also used this when a spambot starts hitting my website for invalid URLs.
So let’s just jump right in with an example:
SPLUNK_START_ARGS=--accept-license \
bash <(curl -s https://raw.githubusercontent.com/dmuth/splunk-lab/master/go.sh)
This will print a confirmation screen where you can back out to modify options. By default, logs are read from logs/, config files and dashboards are stored in app/, and data that Splunk ingests is written to data/.
Once the container is running, you will be able to access it at https://localhost:8000/ with the username “admin” and the password that you specified at startup.
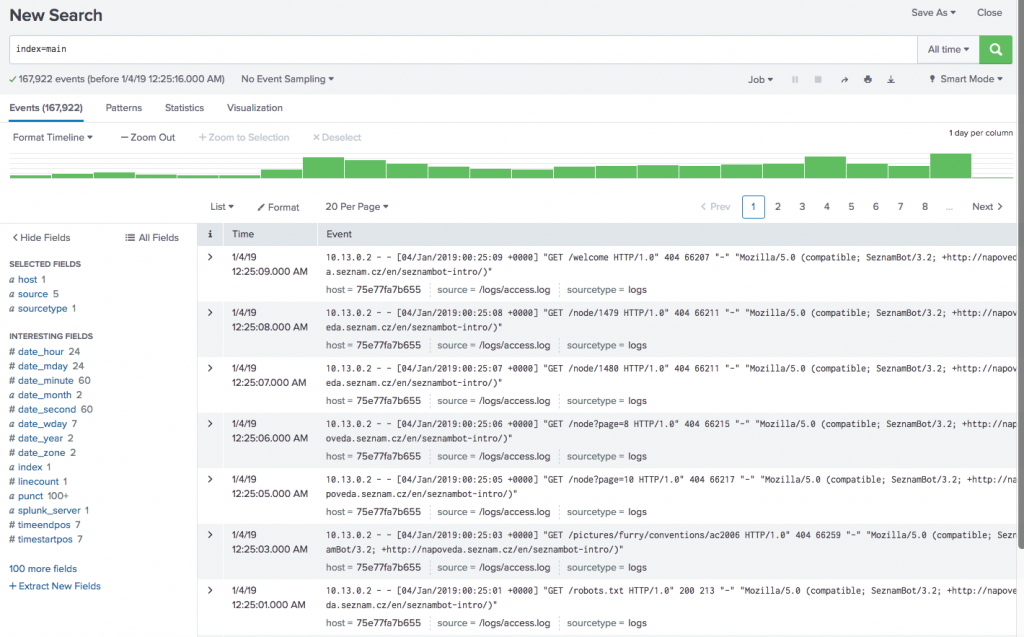
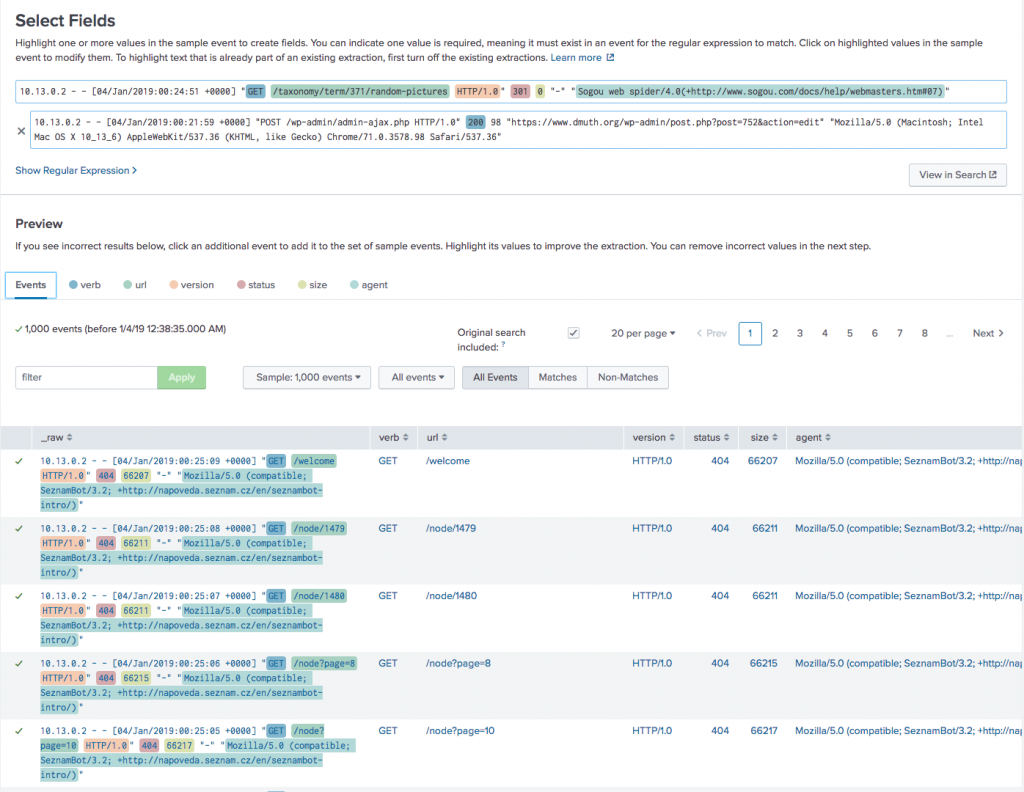
First things first, let’s verify our data was loaded and do some field extractions!


Main Index 

Field Extractions