I’m a big fan of Amazon S3 for storage, and I like it so much that I use Odrive to sync folders from my hard drive into S3 use S3 to store copies of all of my files from Dropbox as a form of backup. I only have about 20 GB of data that I truly care about, so that should be less than a dollar per month for hosting, right? Well…
“You are not your job or how much data you have in S3!”
Close to 250 GB billed for last month. How did that happen?
I’m a big fan of the Discord Musicbot, and run it on some Discord servers that I admin. Wanting to run it on a server, I first created an Ansible playbook and launched a server on Digital Ocean. But after a few months, I noticed that the server was sitting over 90% idle. Surely there had to be a better way.
So I next tried Docker, and created a Dockerized version of the Musicbot. I was quite happy with how much easier it was to spin up the bot, but still didn’t want to run it on a dedicated server on Digital Ocean. Aside from having unused capacity, if that machine were to go down, I’d have to do something manually.
I thought about running it in some sort of hosted Docker cluster, and came across Amazon’s container service. So this post is about creating your own cluster in ECS and hosting a Docker container in it. I found the process slightly confusing when I did it the first time, and wanted to share my experience here.
With the release of SEPTA’s new app, I’ve suddenly been flooded with questions about their API. People wanted to know how stable it was.
Well, I don’t work for SEPTA, which means I don’t have insight into their operations, but I can perform some analytics based on what I have, which is approximately 18 months of Regional Rail train data, read every minute by SEPTA Stats.
Overall Stats
This is all of the data that I have in Septa Stats currently:
Events Since Inception: 26,924,887 events
First Event: Mar 1, 2016 12:00:01 AM
Last Event: Nov 16, 2017 10:33:53 PM
That’s way more events than minutes in that timeframe, and the reason for that is each API query is split into a separate event for each train. So if an API call returns status for 20 trains, that gets split into 20 different events. This is done because Splunk has a much easier time working with JSON that isn’t a giant array. 🙂
I’ve been living in a one-bedroom apartment for the last 15 years. It has mostly suited my needs — I don’t have any hobbies which require lots of “stuff”, and having a smaller apartment means that I can live closer to the city which makes for a shorter commute. In short: my apartment is a good fit for me.
However, there was one thing that got steadily worse over the years: clutter. While I cleaned regularly and could make my way around the apartment just fine, it was the little things that got me: the overflowing bookshelf, the ironing board with clean clothes sitting on it (because I had no room in my dresser), etc.
This was less a closet, and more a disaster area.
Things reached a breaking point a few months ago, when I realized that I needed to do some serious decluttering of my apartment. With the help of my Amazon Prime subscription, I started to order organizing products by the boxful and was able to make my apartment much more inhabitable then before.
That’s not to say I didn’t throw things out — I threw out a bunchof things, donated other things, and put a few more things into my storage unit. If you are trying to declutter your home, you are very likely going to have to throw somethingout. Be prepared for that. If you must, take pictures of the things you’re throwing out, but understand that the key to decluttering is throwing out the things you no longer need.
I’m going to go through the various things I used for organizing. I’ll start with plastic Rubbermaid/Tupperware containers, then move on to trash bags and shelving. Finally, I’ll wrap up with some additional organizing tips.
While S3 is a great storage platform, what happens if you accidentally delete some important files? Well, S3 has a mechanism to recover deleted files, and I’d like to go into that in this post.
First, make sure you have versioning enabled on your bucket. This can be done via the API, or via the UI in the “properties” tab for your bucket. Versioning saves every change to a file (including deletions) as a separate version of said object, with the most recent version taking precedence. In fact, a deletion is also a version! It is a zero-byte version which has a “DELETE” flag set. And the essence of recovering undeleted files simply involves removing the latest version with the “DELETE” flag.
This is what that would look like in the UI:
To undelete these files, we’ll use a script I created called s3-undelete.sh, which can be found over on GitHub:
Hey software engineers! Do you manage servers? Lots of servers? Hate copying and pasting hostnames and IP addresses? Need a way to execute a command on each of a group of servers that you manage?
I developed an app which can help with those things, and my employer has graciously given me permission to open source it.
At my day job, I get to write a bit of code. I’m fortunate that my employer is pretty cool about letting us open source what we write, so I’m happy to announce that two of my projects have been open sourced!
The first project is an app which I wrote in PHP, it can be used to compare an arbitrary number of .ini files on a logical basis. What this means is that if you have ini files with similar contents, but the stanzas and key/value pairs are all mixed up, this utility will read in all of the .ini files that you specify, put the stanzas and their keys and values into well defined data structures, perform comparisons, and let you know what the differences are. (if any) In production, we used this to compare configuration files for Splunk from several different installations that we wanted to consolidate. Given that we had dozens of files, some having hundreds of lines, this utility saved us hours of effort and eliminated the possibility of human error. It can be found at:
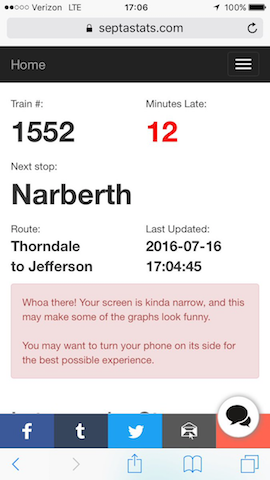
While waiting for a train at Ardmore station yesterday, I decided to check it out on SEPTA Stats to see just how late it was, and where it was. This is what I saw:
Well… that can’t be right. It’s an inbound train, and I had been standing at Ardmore station for the last 10 minutes. No trains came through in that time. What’s going on?
…and 2 new API endpionts, too. But more on those later.
I’m proud to say that there is now a dashboard for the entire Regional Rail system. It is present on both the front page and the “SEPTA System Stats” page:
This new dashboard makes it straightforward to determine the status of the entire Regional Rail system at a glance.
On the heels of yesterday’s post, I’ve introduced dashboards for train lines.
The dashboard will provide a snapshot of the current status of the line, namely the number of trains, average lateness, and how many trains are over 5 minutes late.